The name is kind of misleading, because is not a port to DOS of my ubox MSX lib, but I call this sort of library “ubox” when I’m building them –even if it is for internal use; they exist for Amstrad CPC and ZX Spectrum–. I hope it doesn’t cause any confusion.
After I released Gold Mine Run! I knew that if I wanted to make another game for DOS, I had to extract what I had written for this game and make it a library.
It is true that I could have made part of the work when I wrote the game, but I decided early on during the development of the game that I wouldn’t waste time thinking about abstractions or reusing code when it wasn’t clear that I would be able to finish the game. Now that there is not uncertainty –the game is finished!–, it is time to do the boring stuff.
And it is done, so I have published a repo with ubox lib for DOS. It is pretty much what I used for the game, with some extras –like an asset manager– and, in some parts, cleaner code.
I don’t know if it can be useful to anybody else, but I guess that now that I have the library, I will have to make at least another game to justify the effort. What I’m sure that I’m not going to do is maintain the library as a project to facilitate people to make DOS games; because I did that with the MSX library, and I haven’t enjoyed the experience too much.
So there isn’t documentation, although the library is tiny, so anybody should be able to read the code and figure out how it works, and even adapt it if needed. I’m happy for people to send bug reports and fixes, but I don’t want it to grow in directions that I don’t like –or, specially, that I don’t use–. Feel free to do whatever you want with your version of it, respecting the license (that is).
Regarding what I’m going to do next for DOS, I’m still undecided!
Although the engine and the stream were completed about two weeks ago, that wasn’t really a game: it needed level design and music, both things that I didn’t want to do on the stream.
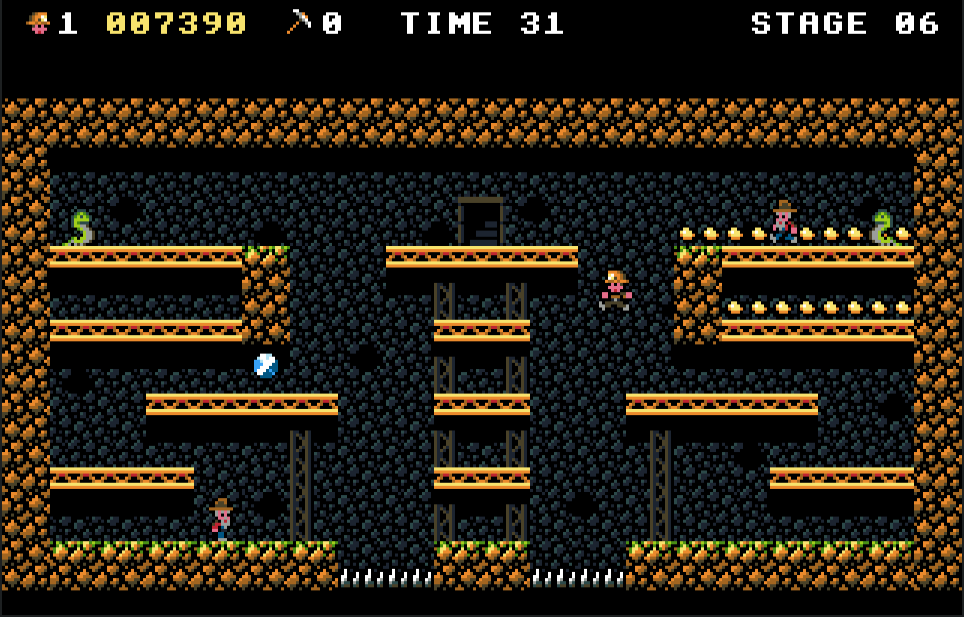
At the end, I decided to add 30 stages, which is about right considering the amount of content –there are limited enemy types–. I didn’t feel like I was repeating myself too much when designing the stages, because there were enough components to keep it somewhat fresh. Yet, it is a small jam game anyway.
I did some gamedev in DOS back in the day, and I feel a bit like I am 25 years late to this, but still had a lot of fun making this game. Without my experience in the last 10 years I wouldn’t have been able to produce Gold Mine Run!, that’s sure. But then I have the feeling I could have made the same game using C and SDL2 –or even Haskell!–, and target current platforms (Linux, Windows and Mac at least). Would it have been the same game? Probably!
Now that this project is out of the way, I can pay more attention to my TODO list. Exciting!
Someone what asking what do you put in a personal website, and it is a shame I can’t remember / find where it was.
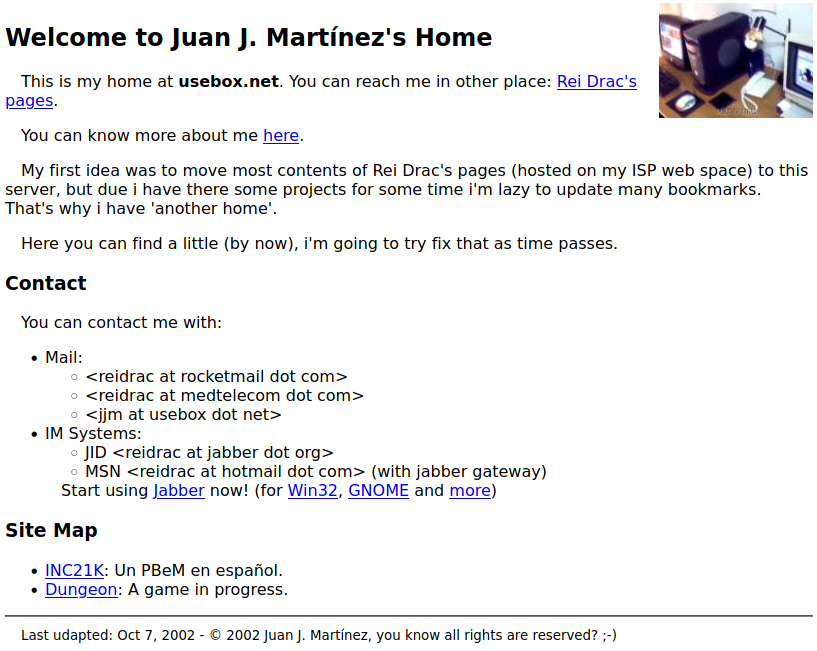
My answer was in the lines of just put together stuff about the things that you are interested in. And lately I have been thinking that this has been my personal website since 2002, but perhaps it doesn’t feel like it now.
This was my personal website in 2002; I'm mildly ashamed that I didn't know how to write my nickname!
In my last re-design –that’s something you do to your personal website every now and then–, moving from a dynamic site managed with Django, I put my games front and centre. Perhaps that is why it doesn’t look that much like a personal website.
This is all subjective, really. May be what for me is a personal website is not what a personal website is for you, but in any case, I think it is important that there are people discussing these topics, and hopefully doing something about it. That is how we escape the big tech companies of 2.0 and their enshittification –my local dictionary didn’t recognise the neologism, so I added it because it is here to stay–.
It is refreshing to click on the surprise link of Wiby and get a different 1.0 website every time, and is not just because of nostalgia, but because all that information should have never been a Facebook page, for example.
And the excuse is not that things cost money and you have to give your freedom away –or become the product–, because you can always find free hosting –and also learn something–.
These are a couple of options that I recommend:
ctrl-c.club: part of the tildeverse it is a very welcoming community where is very easy to create an account and host your website.
Neocities: is it a social network? I guess the original Geocities was a bit like that too. I prefer the club; but this is probably easier to get started.
I mentioned here that I was making a game for the DOS operating system, and that I was going to stream the process. And I did it!
All the videos are available on this playlist on YouTube, a total of 20 videos where I build most of the game from scratch. I didn’t do pixel art, for the most part, and there were a couple of bits that I wrote off camera because it was about solving problems that I didn’t even know if there was a solution, and that type of troubleshooting on stream is very boring.
This is the test screen
The series had some interest, considering that I don’t have that many followers and not many people watch the sessions live –there seems to be more views when I upload the videos to YouTube–. I enjoyed the few occasions when there were people on the chat and we commented on the stuff I was coding, which is one of the big reasons to stream my sessions –the other one is basically sharing, so people can learn or perhaps get inspired–.
I have been consistent as well, streaming Tuesdays and Thursdays from 20:30 GMT for 1 to 2 hours. But I had to add some sessions in between, and that was the main problem with this project: the time was too short.
I have made games with similar scope before, and it took me from 3 to 4 months, so trying to squeeze the same in month and a half… it was probably too much. Besides, this is a new platform and I didn’t have an existing working codebase. That was specially problematic with the sound and the engine design –that at the end works perfectly on a 386DX 33MHz, but it was hard to get there–. In the 8-bit systems I make games for, I don’t start from scratch any more!
As consequence, I won’t be submitting the game to the Jam. Which was one of the possible outcomes.
The game is not finished, and over the next 2 to 4 weeks I will be working on the music and level design, and after that, Gold Mine Run! will be released. Watch this space.
I never liked the user interface too much, it feels slow and bloated, but in general the feature-set is nice, and it definitely works for me. But then GitLab has been making changes that I didn’t like too much –even if they didn’t affect me directly–:
They are copying the bad things I didn’t like in GitHub (achievements? why?), including a push for AI –because all has to have AI now!–.
Their paid tiers are too expensive, meaning that you are in the free tier or you are a business that can justify the cost.
Considering that I’m privileged because I have my own servers and I can self-host, it doesn’t make sense for me to keep using their service if I’m not happy with them. I don’t want to endorse them either, which is something that you indirectly do when use a free service.
The projects I have left in GitHub (50 repos) are all forks, archived and/or I’m not actively working on them –and if at some point I resume some of them, I’ll move them to my servers–. The projects in GitLab, however, are active. So I have to make changes.
I know the move will affect contributions and will make some things harder –although mostly because they will be different–. And that would be true even if I was moving to another hosting service, because that would likely be SourceHut, and it relies on email workflows.
So it is happening: I’m moving out of GitLab. I’m planning changes on the MSX libraries, and that is probably the perfect time to move things around. Now you know why.
I don’t think it is a surprise that a big part of the community around Hacker News is against the idea of copyleft (e.g. licenses like the GPL, AGPL and LGPL to some extent). They are a clear example of what is the result of the corporations getting involved in open source: the more permissive is the licensing, the better. So they can take, and don’t be forced to give back.
Is not an easy topic. When I was at University there was a whole course to learn about laws around software, and that included licenses. It is very easy to get confused, and people often argue about free software vs open source, perhaps because the Free Software Foundation has often been divisive in their way of promoting the philosophical side of open source.
Copyleft is a licensing tool unique to free software. It is designed to encourage the proliferation of free software and protect free software from being incorporated into non-free works. This works by giving you not only the right to share your improvements, but the obligation to share your improvements under some conditions. It is very important to understand these obligations when re-using copyleft software in your own work.
And that obligation is what is referred as virical, and what the corporations don’t like. Specially in today’s take of computing, with cloud computing and software as a service making them all that money.
I used to be an open source / free software advocate 20 years ago, but I stopped because, at some point, it looked to me like we had accomplished some of our objectives (and I guess I got tired). But the truth is that things aren’t as good as they could be.
What was always front and centre was user freedom, something that open source ideas don’t really care about. Not because the licenses are different –because most open source is free software–, but because what it was always important was the copyleft.
So we need more free software, and Write Free Software is a very good resource that explains all you need to know –not really, you don’t need to know all that; but if you make software, it should help you–. It isn’t as confrontational as the Free Software Foundation resources, and definitely easier to read!
I guess is a sign or getting old when we stop tinkering with Linux distros, desktop environments, and windows managers. After Gnome changed to their new idea of desktop in Gnome 3 –back in 2011–, I tried hard –and for an embarrassing amount of time, considering I wasn’t happy–, and finally landed on XFCE. It was a weird time in the Linux desktop space.
XFCE was a bit different to the Gnome 2 experience I liked, but when I tried XFCE 4 on Debian Jessie it felt like home.
And don’t get me wrong: it has never been perfect. There are some issues that have been bugging me for years, like the screen lock getting stuck after suspending –and because it is rare, plus not being clear who owns the bug, it seems unlikely it will be fixed–, but as a desktop environment it is out of the way. What else can you ask?
Then I know a lot of people using tiling window managers, to the point that I may have been the only one not using one already. I had a few key bindings in XFCE to give me some limited features of that type of window management, but I was wondering if there was something I was missing out.
So I finally tried i3wm after some research, because it looked like the most user friendly –despite having a steep learning curve, like all of them, but that’s true for most power tools–. I installed it alongside my XFCE, gave it a quick go, and I put it on the back burner because it wasn’t the right time to disrupt my workflow –I was finishing Hyperdrive–.
Until last week, that I gave it another go, and I love it.
i3wm feels fast and responsive, and being used to the vim + tmux experience, it felt a very natural way of working. Sure, it needed some effort to configure, and I don’t think I’m finished with it, but I’m getting there.
Currently I still depend a bit on having XFCE installed, which is not a problem, because I still use Thunar for example to browse files. If at some point I install a system from scratch, then I will do a more focused selection of applications I really use and I may not need a full desktop environment that I won’t use.
My i3 configuration is available, and it will need some time to get close to that perfection I’m talking about. I have passed the test of streaming with OBS, which was the part that I initially thought it would be “harder”.
However, currently I have a couple of issues:
I’m using xfce4-screenshooter to take screenshots, and works beautifully, but it doesn’t give me the option to put the screenshot in the clipboard; which is mildly annoying.
I’m using kazam to record videos, and when I try to select the window to capture, it goes wrong and I can’t see the windows. If I click where the window should be, it does the capture just fine.
Other than that, I’m converted already. And if (when?) I have to move to Wayland, I can move to Sway without much work –other than not using XFCE apps unless it has Wayland support by then!–.
So I guess I’m not that old yet, because there’s some tinkering spirit still in me.
Update (2023-07-08): because I got a couple of emails mentioning it and I had solved “the issue” already, let me update on the screenshot “issue”.
Just run XFCE’s climpan! In X11 there is no shared clipboard, so you need an application that can keep that data when the screenshot tool is gone. My i3 config has now:
Then you just need to configure it to your personal taste. Because XFCE didn’t show the icon of the application when it was running, I didn’t know it was there.
So it all started because a copule of people I follow on Mastodon are into DOS game development, and they are doing very neat stuff. I looked at some of the games and I saw that DJGPP is still around! It was my first ever contact with GCC, GNU and free software –although I didn’t notice that last part, or I didn’t understand it–. It surely changed me, like having a ZX Spectrum as a kid had a lasting effect on my career, before I started using Linux.
I made a few programs with it, with different levels of success. Some of them even got “published” on a magazine at the time –via one of the sections, you could send them your stuff and they would comment it and include it in the CD-ROM distributed with the magazine–. Unfortunately I never managed to finish a game.
I was proud of this one!
Today I’m better equipped on the knowledge side of things, and I have a few finished (and released) games under my belt. I also think I have better tools and computing environment today, so I thought: would it be that hard to make a DOS game today?
That type of question has always worked for me. That is how I got started making ZX Spectrum games in 2014, and a few other systems after that. I always answer if I could and never wonder if I should, which I will leave to you dear reader to decide if is a good or a bad thing.
Besides, recently I have passed the 4 years mark doing streaming of my coding sessions –with 40+ videos uploaded to YouTube–, and I thought it would be a nice experience to try and make a simple DOS game on the stream. There is also a DOS game Jam happening, so it is all there!
Obviously, this is yet another project, that adds more distractions and things to my already long TODO list; but considering that it should be quick, there is nothing to worry about, isn’t it?
It won’t be a tutorial, but I tend to explain what I do on the stream, and the source code is available. It all depends on the skills of the person following the series, but it could work as a good introduction or, at least, as inspiration.
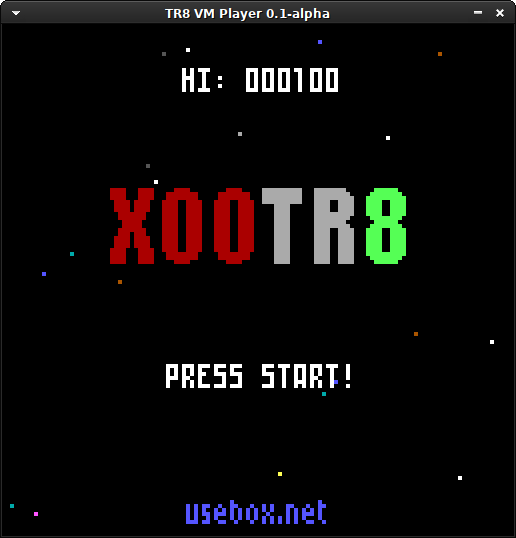
Not much to show, but this is promissing!
That doesn’t mean all the streams will be “making a DOS game”, but until the game is completed, there are chances they are the majority of the videos. Nothing is happening with my unnamed Haskell game for PC, the TR8 fantasy console, or Outpost for the ZX Spectrum. Those are still on and healthy.
I got the inspiration from the fantastic rasm –a Z80 assembler–. rasm supports a number of formats for input and output, and the input goes way beyond the “include” we can find in some assemblers.
As part of my TR8 fantasy console I have implemented .incpng "file.png", that does the following –from the docs–:
.incpng “filename”
Read the PNG image and add the content to the output at current position. The
image colors will be matched with the TR8 palette and any non-matching color
will be considered transparent and the index 128 will be used.
So it is like a “include binary”, but it understand and reads a PNG file, including the pixel data in the assembled output.
It converts the image to red, green and blue triplets –RGB values– and maps them to the EGA default palette –which is the palette I’m currently using–. If a RGB value doesn’t match the EGA palette, the tool uses 128. That value is used with the blitter if transparent is enabled to treat it as transparent –otherwise it will be black–.
The menu of the example game uses 'incpng' for the title
It is so convenient to use! But obviously, this is only because I’m writing the assembler myself –and it has many limitations, currently–. Using other compilers, very often the options are very limited, and that is when my conversion tools written in Python save the day.
Over the years I have been playing with the idea of writing interpreters and compilers, and I say idea on purpose, because I haven’t been very successful at it. Something similar happens with operating systems and virtual machines, although I have been a bit better with the latter, I had many projects started over the years without results.
Considering that I have been doing game development consistently for almost 10 years now, the idea of a fantasy console is so perfect if you want to write those, that I would say it was almost inevitable I made one.
It is all very work in progress and, instead of spending a lot of time planing and designing without getting to make anything, I decided to start implementing and put together things as I go. And you can tell when you look at the design of the 8-bit CPU.
Without getting in too much detail, an example program:
.org0; address of the frame interrupt vector
.equINT_VECT0xff00; setup an int handler so we
; can use the frame int to sync
lda, >INT_VECTldx, <INT_VECTldb, <int_handlerld [a : x], bincxldb, >int_handlerld [a : x], b; enable interrupts
cif; loop filling the screen with one
; colour cycling the whole palette
ldb, 0loop:
callfillincbandb, 15; wait 1 second
ldx, 60wait_loop:
haltdecxbnzjmpwait_loopjmploop; fill frame-buffer with a color in reg b
fill:
lda, 0xbfldx, 0ldy, 0x40fill_loop:
ld [a : x], bincxbnojmpfill_loopincadecybnzjmpfill_loopretint_handler:
iret
That may give a bit of a taste of what is TR-8.
At the moment I’m working on three essential components:
a virtual machine for the CPU
an assembler
a “player” that uses the virtual machine and provides the other bits of that make it “a console”
All written in C –hopefully portable–, with SDL2 for the player.
As I say, it is a work in progress, but this is what I have decided so far:
Display: 128 x 128 pixels 16 colors (using the default EGA palette for now)
Memory: 64K
CPU: TR-8, 8-bit, 8M instr/sec (for now, likely make it slower when I add the hardware blitter)
Sound: TBD, likely to be either a PSG or perhaps FM (OPL3?)
Programming: ASM
The TR-8 CPU is inspired by the 8-bit CPUs I have programmed: the Z80 and the 6502; but also the MIPS (specially on how I’m encoding the instructions). This is not about a good design but about having some fun.
The main features of the CPU are:
16-bit registers: stack pointer (SP) and program counter (PC)
a frame buffer (16K of RAM as video RAM; I thought about implementing a VDP but then I realised I was copying the MSX!)
I don’t know how far I’m going to get. I guess I will implement enough to feel satisfied, perhaps making a game for it, and that’s probably it. I don’t expect anybody using this, when you can make games for actual 8-bit machines –or more user-friendly fantasy consoles like the Pico-8 or the Tic-80–.